1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variableimport torch.nn.functional as F
import numpy as npimport torchvision
from torchvision import datasets,models,transforms
import matplotlib.pyplot as plt
import time
import copy
import os
data_dir = '/content/drive/MyDrive/pytorch_learning/hymenoptera_data' # 数据存储总路径
image_size = 224 #图像大小为224*224像素
# 加载过程对图像进行如下操作
# 1.随机从原始图像中切下来一块224*224大小的区域
# 2.随机水平翻转图像# 3.将图像的色彩数值标准化
train_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'),
transforms.Compose([
transforms.RandomResizedCrop(image_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
)
# 加载校验数据集
val_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'),
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
)
# 创建相应数据加载器
# 读取数据中分类类别数
num_classes = len(train_dataset.classes)
# 模型迁移
net = models.resnet18(pretrained=True)
for param in net.parameters():
param.requires_grad = False# 预训练方式迁移num_ftrs = net.fc.in_features # ResNet18最后全连接层的输入神经元个数
net.fc = nn.Linear(num_ftrs, 2) # 拿掉ResNet18的最后两层全连接层,替换成输出单元为2的全连接层criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr=0.0001,momentum=0.9)
use_cuda = torch.cuda.is_available() # 判断是否可以使用GPU进行加速
dtype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
itype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
net = net.cuda() if use_cuda else net
def rightness(predictions, labels):
pred = torch.max(predictions.data, 1)[1] # 对于任意一行(一个样本)的输出值的第1个维度,求最大,得到每一行的最大元素的下标
rights = pred.eq(labels.data.view_as(pred)).sum() #将下标与labels中包含的类别进行比较,并累计得到比较正确的数量
return rights, len(labels) #返回正确的数量和这一次一共比较了多少元素
if __name__=="__main__":
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=4,shuffle=True,num_workers=4)
val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=4,shuffle=True,num_workers=4)
print(use_cuda)
record = [] # 记录准确率等数值的容器
num_epochs =20
net.train(True)
for epoch in range(num_epochs):
train_rights = []
train_losses = []
for batch_idx, (data,target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
if use_cuda:
data, target = data.cuda(),target.cuda()
output = net(data) # 完成一次预测
loss= criterion(output,target)
loss =loss.cpu() if use_cuda else loss
optimizer.zero_grad() # 清空梯度
loss.backward()
optimizer.step()
right = rightness(output,target)
train_rights.append(right)
train_losses.append(loss.data.numpy())
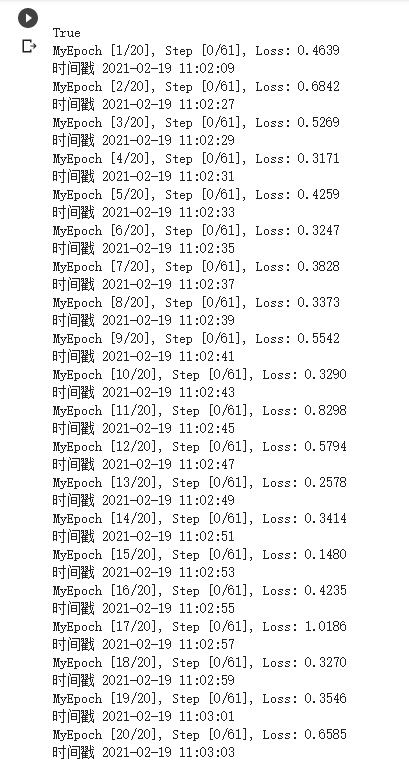
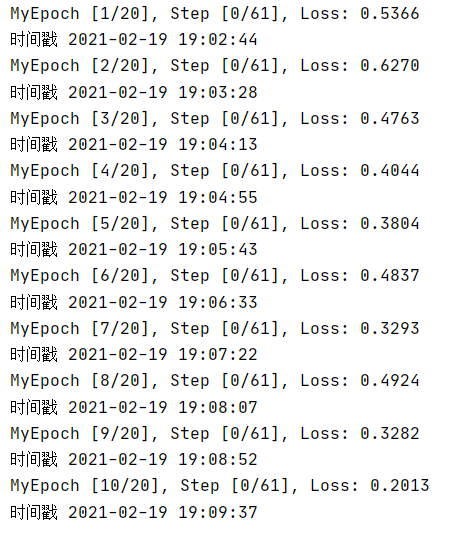
if batch_idx %100 == 0:
print('MyEpoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, batch_idx, len(train_loader), loss.item()))
print('时间戳', time.strftime("%Y-%m-%d %H:%M:%S"))
|